AWS Lambda was a clear choice for our model delivery system, due to its serverless architecture and low cost. However, Lambda functions can only be 250 MB unzipped, which posed a problem to us. Parasite ID’s first classification algorithm was a neural network with almost 18 million parameters! It requires Keras (built on TensorFlow) to run, and TensorFlow is 350 MB alone. This post will shed some light on how we implemented the model and hopefully help others with similar goals.
First I familiarized myself with Serverless using this tutorial. Once I could deploy simple packages, I replaced the code in handler.py with my own script to classify images. After I loaded Keras, TensorFlow, and scikit-image into my virtual environment, the function would no longer deploy because it was too big. Here are the steps I took to reduce the size:
-
Replace scikit-image with the smaller package Pillow.
-
Create a virtual environment outside of the function directory. I still used
pip freeze > lambda_function/requirements.txtto specify the requirements to serverless. However, it allowed me to use the optionzip: true in serverless.yaml(be sure to modify your handler script as well – see this article for instructions). This cheats the 250 MB unzipped requirement by leaving the dependencies zipped within the unzipped folder that is uploaded to Lambda. When they are imported, they are unzipped into the/tmp/folder, which has a limit of 512 MB. I also had to specifyvendor: /path/to/virtualenvironment/lib/python3.6/site-packages(see the documentation) in order to point serverless to the source files. -
This was still too large, so I used Ryfeus’s precompiled packages. They are found here. I downloaded Keras_tensorflow and pointed serverless to those packages with
vendor: /home/ec2-user/Keras_tensorflow/source. I saw that it is only available for python 2, so I created a new virtual environmentvirtualenv venv –python=python2, activated the environment withsource venv/bin/activate, and installed the remaining libraries I needed (in this case, justpip install Pillow). All that was left was to runpip freeze > lambda_function/requirements.txtand serverless handled the rest. -
The function uploaded! I thought I had made it. But alas, when the code imported our model, it couldn’t read it. It turns out, Ryfeus uses Keras v2.0.6, and we had compiled our model on a higher version. So I recreated the structure of the model from scratch (using our modeling code) in Keras 2.0.6, then added the weights with
model.load_weights(model_weights.h5). After saving the architecture in a .json file in S3 along with the weights, they were accessible by the lambda function and we were in business. This may have corrupted our model, so all of our future modeling will be done in Keras 2.0.6 to avoid this step.
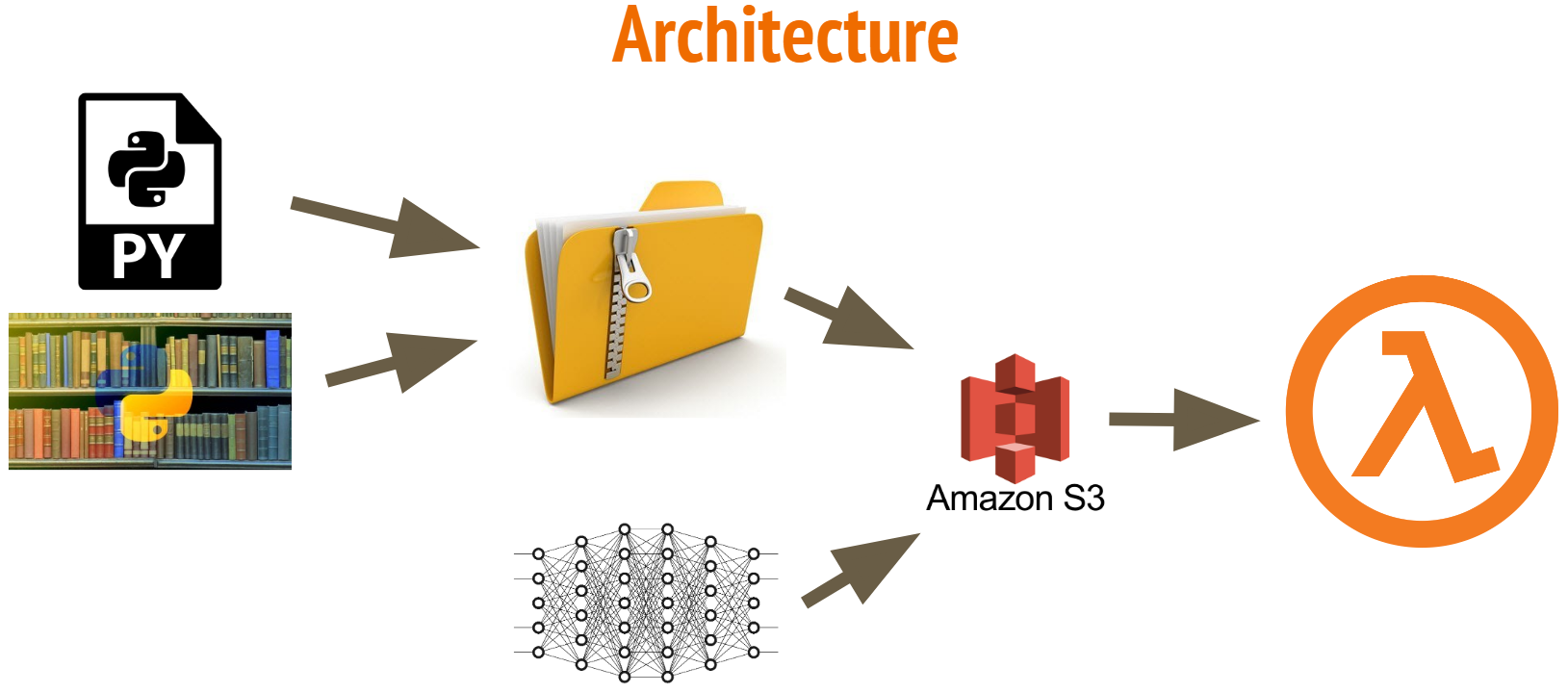
The beauty of this system is that our model can be updated with no code – we simply replace the files in S3 that hold our model architecture and weights, and they are the ones accessed by the Lambda function. The pipeline is left unchanged, and it is immediately deployed to our development lambda for testing. If it works, we rename the files so that they will be accessed by the production lambda and voila, our model is implemented!
