Edited on August 30, 2019.
After we had a functional transfer learning model, we were feeling good about Parasite ID. Then, somehow, Cameron accidentally uploaded a picture of a hammock that Vicki had originally taken on her vacation to the web app, and the app predicted that the hammock had schistosomiasis. This was a very sobering result for us, since we had been optimistic about our model’s performance. We were worried that while the model might be good at classifying parasites, anyone who wasn’t a data scientist and didn’t understand how the model was built could test it out on their own images, and if we kept predicting parasites on hammock images, it would hurt our credibility.

Ultimately, this result made sense. There were no images of hammocks in our train or test image sets. All we had were parasite eggs, which tend to have clearly defined edges, and negatives, which either have nothing or stool debris, neither of which have edges. Seeing a new image that was completely different from what it had trained on confused the model.
To solve this, we employed several different approaches. First, we spent hours adding bounding boxes of background stool from all our base images. Previously, we didn’t have enough negative images, and highlighting confusing debris for the model to learn on helped strengthen its understanding of the negative class. This alone solved the original hammock problem, but we weren’t satisfied there.
When the model makes a prediction, it returns an array of 10 probabilities—one for each class (9 parasite classes plus the negative class). Our original approach was simply to take the class that had the highest probability. However, that probability could be very low; some were below 50% confidence, indicating the model was confused and conflicted.
We took a close look at the images where the model was confused and probabilities were below 90%. Nearly all were blurry or the parasites were obscured or cut off. In some, it would have been easy for a trained parasitologist to make a mistake, or at least to not be confident in her prediction. On nearly half of these low-probability images, the model made an incorrect classification.
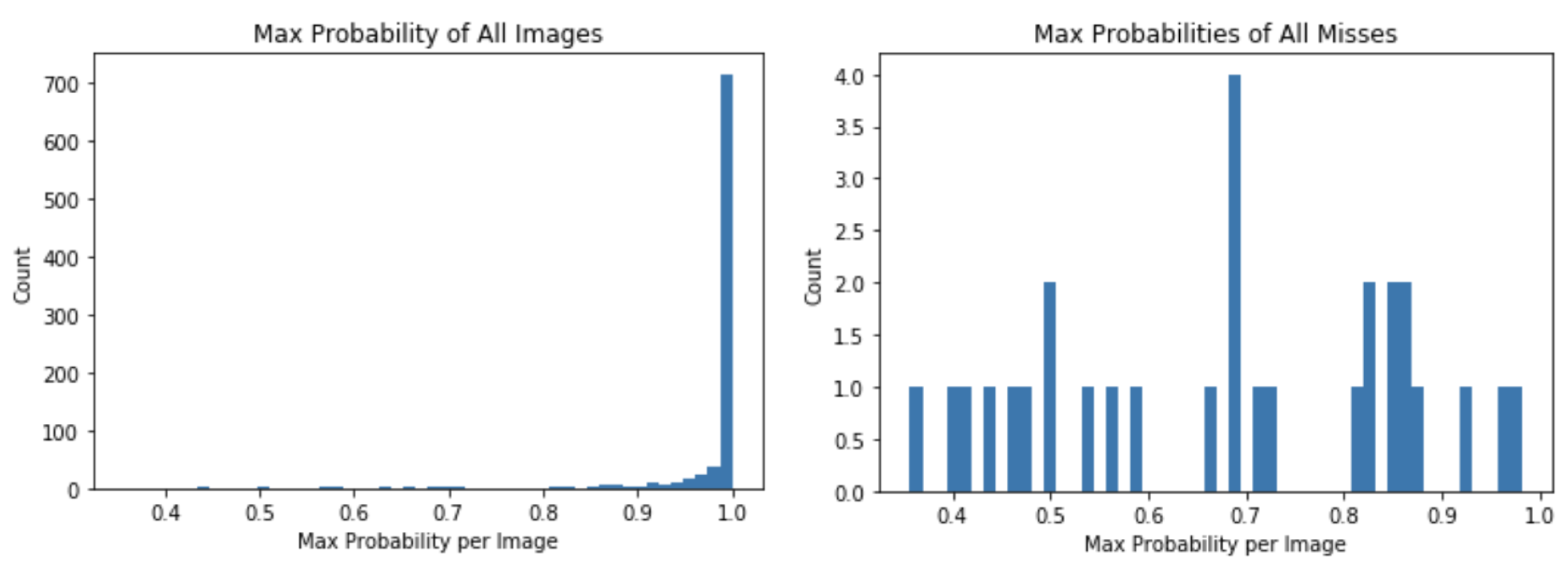
In our new approach, we do not return a prediction if the model is less than 90% confident in its prediction. Instead, the web app prompts the user to take a better image, ideally one that is less blurry or obscured. There are numerous ethical reasons why this is a good idea; we don’t want the model making predictions where it is not very confident, particularly given the costs of false negatives. In our test dataset, instituting this new threshold only cut out around 7% of the images, meaning the model could confidently predict on over 93% of the images. Within that group, the model only misclassified 2 of over 800 images, an accuracy of »99%. Prior to that, accuracy had peaked around 97.3%.
One final method we tried was to actually add a random selection of a few hundred images from ImageNet to the training data as negatives. Results were a bit mixed; this seemed to have slightly confused the model about what to look for in the negative class. It is a method we will continue to explore.
To test, we loaded the hammock and numerous other non-parasites: family photos, pictures of beaches, mountains, anything we could test the model on. Nearly all were came negative, and the worst case scenario, the model returned the “please upload a better image” prompt. Furthermore, these additions to the model made performance on in-sample data better. With these changes, we feel more strongly about ParasiteID’s ability to outperform a human at classifying parasites. And maybe even hammocks.